
در این مقاله قصد داریم به معرفی ویونت (WaveNet) بپردازیم که در واقع یک مدل تولیدی ژرف (deep generative model) از شکل موجهای صوتی خام است. ویونت با پشت سر گذاشتن تمامی سامانههای تبدیل متن به گفتار قادر به تقلید بی کموکاست از صدای انسانی است و توانسته است فاصله خود را با صدای طبیعی انسان، بیش از ۵۰ درصد کاهش دهد.
همچنین نشان میدهیم که شبکهای مشابه با ویونت را میتوان برای ترکیب دیگر سیگنالهای صوتی از قبیل موسیقی استفاده کرد و نمونههای قابل توجهی از قطعات پیانو را به طور خودکار تولید کرد.
گفتوگو با رایانهها
گفتوگو و تعامل با رایانهها و رباتها همواره از رؤیاهای دیرباز بشر بوده است. طی سالیان اخیر، با باز شدن پای شبکههای عصبی ژرف به دانش علوم رایانشی، تحولی انقلابی در توانایی کامپیوترها برای درک گفتار طبیعی انسان رخ داده است (مانند جستوجوی صوتی گوگل). با این حال، گفتار تولید شده توسط کامپیوترها (فرآیندی که معمولا از آن با عنوان سنتز گفتار یا تبدیل متن به گفتار (TTS) یاد میشود) هنوز تا حد زیادی بر روشی به نامConcatenative TTS یا تبدیل متن به گفتار به شیوهی الحاقی مبتنی است. در این روش، یک پایگاه داده بسیار بزرگ از قطعات گفتاری ضبط شده یک فرد تهیه شده و سپس این قطعات همانند تکههای یک پازل کنار هم قرار میگیرند تا یک کلمه یا جمله قابل فهم تولید شود. استفاده از این شیوه، اصلاح صوت یا گفتار تولید شده را دشوار میکند. برای مثال، در این روش نمیتوان گوینده را تعویض کرد یا نوا یا تکیهی صدای گفتار را تغییر داد.
همین کاستیها منجر به روی آوردن به فناوری Parametric TTS (تبدیل متن به صدا به شیوه پارامتری) شده است. در این روش، تمامی دادههای موردنیاز برای تولید گفتار در قالب پارامترهای یک مدل ذخیره میشوند و میتوان محتویات و ویژگیهای گفتار تولید شده را با تغییر ورودیهای اعمال شده به مدل کنترل کرد. با این حال، صدای تولید شده توسط این روش به نسبت شیوه الحاقی، شباهت کمتری به صدای طبیعی انسان دارد. به طور معمول، مدلهای پارامتری فعلی، سیگنالهای صوتی را با عبور خروجی خود از الگوریتمهای پردازش سیگنالی موسوم به vocoder-ها تولید میکنند.
ویونت این قاعده را بر هم زده است و شکل موج خام سیگنال صوتی را به طور مستقیم به یک نمونه مدل میکند. همچنین گفتار تولید شده به کمک این برنامه بسیار طبیعیتر به نظر میرسد و استفاده از شکل موجهای خام صوتی نیز به این معناست که ویونت میتواند هرگونه صوتی از جمله موسیقی را نیز مدل کند.
ویونت
پژوهشگران معمولا از مدلسازی صوت خام اجتناب میکنند؛ چرا که به سرعت دچار وقفههای منظم یا به اصلاح تیکتیک میشود. دلیل آن این است که معمولا در مدلسازی، بیشتر از ۱۶ هزار نمونه در ثانیه در مقیاسهای زمانی متفاوت پردازش میشوند. ساختن یک مدل خودهمبسته که در آن پیشبینی هر یک از نمونههای یاد شده متأثر از تمامی نمونههای قبلی است، کار بسیار چالشبرانگیزی است (در مباحث آماری گفتار، هر توزیع پیشگو (predictive distribution) مشروط بر تمامی مشاهدات پیشین است). گفتنی است که مدل خود همبسته یاAutoregressive model نوعی از فرایند تصادفی است که غالباً جهت مدلسازی و پیشبینی انواع مختلفی از پدیدههای طبیعی و اجتماعی به کار میرود.
با این حال، مدلهای PixelRNN و PixelCNN که پیشتر در اوایل سال جاری توسط محققان دیپمایند(DeepMind) معرفی شدند، نشان دادند که تولید تصاویر طبیعی پیچیده نه تنها با استفاده از یک پیکسل در هر زمان بلکه با بهرهگیری از یک کانال رنگ در هر زمان، نیازمند هزاران پیشبینی به ازای هر تصویر است. این پدیده، الهامبخش محققان Google برای انطباق مدل دو بعدی PixelNets به یک ویونت تک بعدی بوده است.

انیمیشن بالا نشان میدهد که ساختار یک ویونت به چه ترتیب است. یک ویونت در واقع یک شبکه عصبی پیچشی کامل (convolutional neural network) است که در آن هر یک از لایههای پیچشی با ضرایب تجانس متفاوت به میدان تأثیر (receptive field) آن اجازه میدهد به صورت نمایی و ژرف رشد کند و هزاران گام زمانی را پوشش دهد.
در هنگام آموزش شبکه عصبی، دنبالههای ورودی همان شکل موجهای واقعی ضبط شده از یک گوینده انسانی هستند. پس از آموزش، میتوان از این شبکه برای تولید یک گفتار ترکیبی نمونهبرداری کرد. در هر مرحله از نمونهبرداری از تابع احتمال محاسبه شده با شبکه، یک مقدار تولید میشود. این مقدار سپس به ورودی خورانده و یک پیشگویی جدید برای گام بعدی ساخته میشود. ساختن نمونهها به این روش به صورت یک مرحله در یک زمان، از نظر رایانشی بسیار گران تمام میشود؛ اما محققان دریافتهاند که این روش برای تولید یک نمونه صوتی پیچیده و واقعی بسیار ضروری است.
عملکرد شگفتانگیز
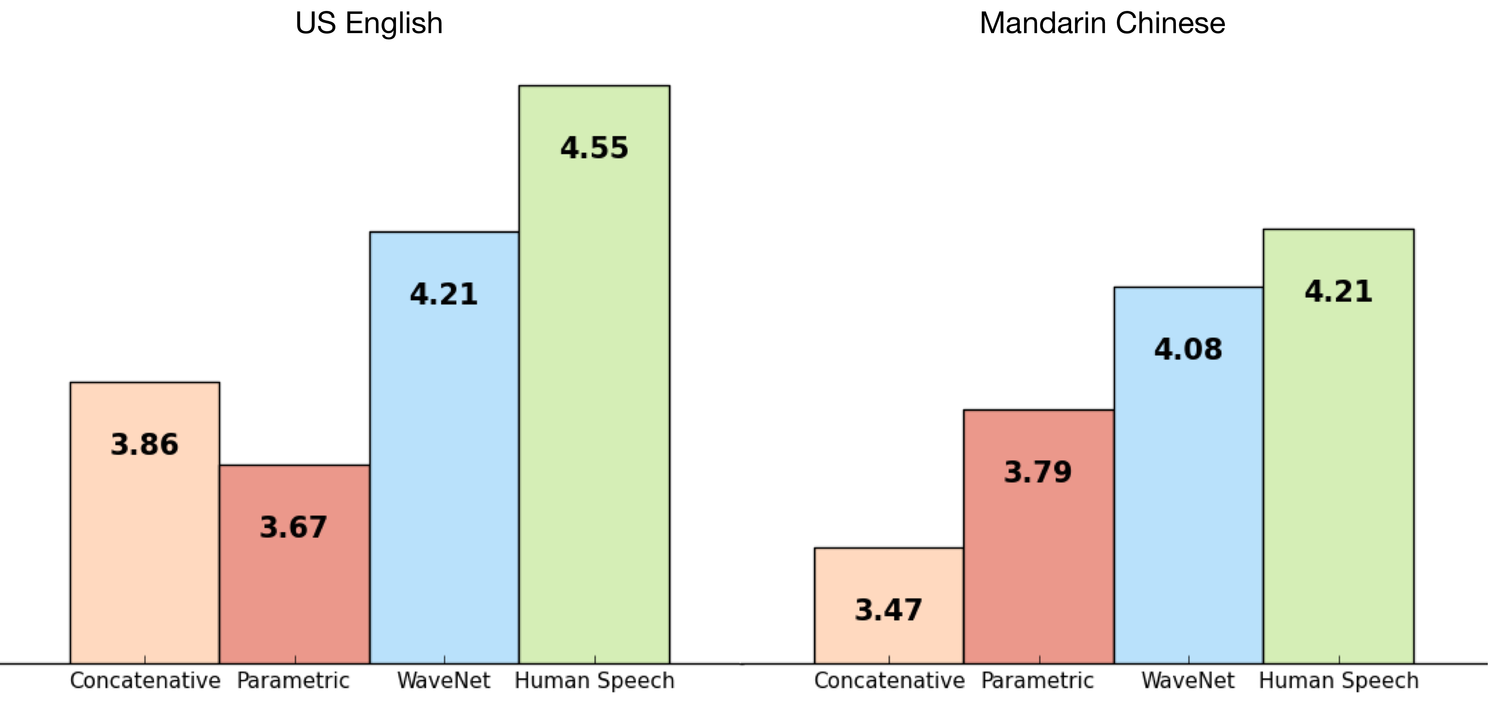
پژوهشگران گوگل، ویونت را با استفاده از برخی از مجموعههای دادههای TTS گوگل آموزش دادند تا بتوانند عملکرد آن را ارزیابی کنند. نمودار زیر، کیفیت ویونت را در مقیاس ۱ تا ۵ در مقایسه با بهترین سامانههای TTS (تبدیل به متن گفتار) کنونی و همچنین گفتار انسانی (با استفاده از روش ارزیابی میانگین نظرات) نشان میدهد. گفتنی است که روش ارزیابی میانگین نظرات یا بهاختصار MOS یک معیار استاندارد برای سنجش کیفیت صدا است. در این روش، جملات سنتز شده برای شرکتکنندگان پخش شده و آنها نسبت به کیفیت نوای گفتار، رعایت تکیهها، آهنگ، احساسات و مانند آن نظر میدهند و سپس از میانگین نظرات آنها برای محاسبه MOS استفاده میشود. همانطور که در نمودار زیر میبینید، ویونت، شکاف بین عملکرد بهترین سامانههای متن به گفتار و انسان را بیش از ۵۰ درصد برای هر دو زبان انگلیسی و ماندارینی (گروهی از زبانهای چینی) کاهش داده است.
سامانه کنونی TTS گوگل برای هر دو زبان چینی و انگلیسی از جمله بهترین سامانههای موجود در جهان است؛ بنابراین استفاده از یک مدل برای بهبود عملکرد آن در هر دو زبان، دستاورد بسیار بزرگی محسوب میشود.
در ادامه تعدادی نمونه از هر سه سامانه تبدیل متن به گفتار آورده شده است که میتوانید آنها را بشنوید و با هم مقایسه کنید:
انگلیسی آمریکایی (US English):
روش پارامتری
روش الحاقی
ویونت
چینی ماندارین (Mandarin Chinese):
روش پارامتری
روش الحاقی
ویونت
ارائه متن با جزئیات کامل به ویونت
برای تبدیل متن به گفتار با استفاده از ویونت، باید متن موردنظر با جزئیات کامل به آن داده شود. محققان برای این کار، متن را به رشتهای از ویژگیهای زبانی و آوایی تبدیل میکنند (که حاوی اطلاعاتی در مورد واجها، هجاها، کلمات و غیره است) و سپس آن را در اختیار ویونت قرار میدهند. این یعنی اینکه پیشبینیهای شبکه ویونت نه تنها به نمونههای صوتی پیشین بلکه به متنی که میخواهیم به آن بدهیم نیز وابسته است.
اگر شبکه عصبی ویونت را بدون رشتههای متنی آموزش دهیم، این شبکه کماکان دست به تولید گفتار میزند؛ اما مجبور است آنچه را که میگوید، برای خوشایند به نظر آمدن، تغییر دهد. همانطور که در نمونههای صوتی زیر قابل شنیدن است، آوای خروجی کمی درهم و برهم میشود؛ چرا که کلمات واقعی با کلمات ساختگی خود شبکه جایگزین شدهاند.
گفتنی است که آواهای غیرکلامی از قبیل صدای نفس کشیدن و حرکات دهان نیز توسط ویونت تولید میشوند که نشان از انعطافپذیری ستودنی یک مدل صوتی خام دارند.
همانطور که از نمونههای صوتی زیر قابل شنیدن است، یک ویونت منفرد میتواند ویژگیهای صداهای متفاوت را اعم از صدای زن یا مرد یاد بگیرد. پژوهشگران برای اینکه مطمئن شوند که ویونت میداند از کدام صدا برای خروجی گفتار خود استفاده کرده است، هویت گوینده را برای او تعریف کردند. جالب است بدانید که محققان در ادامه دریافتند در مدلسازی یک گوینده، آموزش صداهای متفاوت به نسبت آموزش یک صدای منفرد، منجر به عملکرد بهتر ویونت میشود که این خود بیانگر نوعی یادگیری انتقالی است.
همچنین با تغییر هویت گوینده، میتوان از ویونت برای ادای یک جمله با اصوات متفاوت استفاده کرد:
به طور مشابه میتوان ورودیهای دیگری از قبیل احساس و لهجه را به مدل ویونت ارائه کرد که بهنوبه خود میتواند گفتار خروجی تولید شده را متنوعتر و خوشایندتر کند.
ساخت موسیقی
از آنجا که میتوان از ویونت برای مدلسازی هر نوع سیگنال صوتی استفاده کرد، محققان برای سرگرمی سعی کردند که از این برنامه برای تولید موسیقی بهره ببرند. آنها برخلاف آزمایشهای TTS، این بار شبکه را به دنبالههای ورودی مشروط نکردند تا به آن بگویند چه چیزی را اجرا کند؛ بلکه به سادگی هر چه تمامتر به آن اجازه دادند هر چه میخواهد، تولید کند. آنها ویونت را با مجموعهای از آهنگهای پیانوی کلاسیک آموزش دادند و شاهد تولید نمونههای جالبی بودند که برخی از آنها در ادامه آورده شده است:
ویونت فرصتهای زیادی را به روی سامانههای تبدیل متن به گفتار، تولید موسیقی و مدلسازی صوتی میگشاید. این واقعیت که این برنامه از شبکههای عصبی ژرف برای تولید تمامی گامهای زمانی به طور مستقیم در فرکانس صوتی ۱۶ کیلوهرتزی استفاده میکند، شگفتانگیز است و همین باعث شده از پیشرفتهترین سامانههای تبدیل متن به گفتار یک سر و گردن بالاتر باشد. پژوهشگران به شدت مشتاق هستند که ببینند در آینده چه کارهای دیگری را میتوانند با این فناوری به سرانجام برسانند.
.: Weblog Themes By Pichak :.
